

Authors:
(1) Oleksandr Kuznetsov, Proxima Labs, 1501 Larkin Street, suite 300, San Francisco, USA and Department of Political Sciences, Communication and International Relations, University of Macerata, Via Crescimbeni, 30/32, 62100 Macerata, Italy ([email protected]);
(2) Dzianis Kanonik, Proxima Labs, 1501 Larkin Street, suite 300, San Francisco, USA;
(3) Alex Rusnak, Proxima Labs, 1501 Larkin Street, suite 300, San Francisco, USA ([email protected]);
(4) Anton Yezhov, Proxima Labs, 1501 Larkin Street, suite 300, San Francisco, USA;
(5) Oleksandr Domin, Proxima Labs, 1501 Larkin Street, suite 300, San Francisco, USA.
Table of Links
1.1. The Blockchain Paradigm and the Challenge of Scalability
1.3. Our contribution and 1.4. Article structure
2. Conceptualizing the Problem
3. Our Idea for Optimizing Trees in Blockchain
4. Efficiency of adaptive Merkle trees
5. Algorithm for Merkle Tree Restructuring
6.2. Example 1.1: Binary Tree Restructuring Through Leaf Node Swapping
6.3. Example 2.1: Restructuring a Non-Binary Tree by Adding a Single Leaf
6.4. Example 2.2: Restructuring a Non-Binary Tree Through Leaf Pair Swapping
6.5. Example 2.3: Restructuring a Patricia-Merkle Tree Fragment Through Leaf Pair Swapping
7. Path Encoding in the Adaptive Merkle Tree
8.2. Technology and Advantages
9.2. Comparison with Existing Solutions
4. Efficiency of adaptive Merkle trees
In this work, we delve into the comparative complexity of data integrity verification between the conventional balanced Merkle Tree and the proposed adaptive Merkle Tree model. The balanced Merkle Tree's average path length is determined by
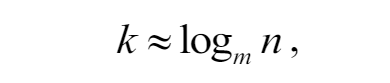
here m represents the maximum allowable number of child nodes per node (the arity of the tree), and n is the count of unique symbols within the alphabet.
Conversely, the adaptive Merkle Tree's average path length mirrors the average length of a Huffman code, calculated as the weighted sum of all code lengths, with the probabilities of the corresponding symbols serving as weights:
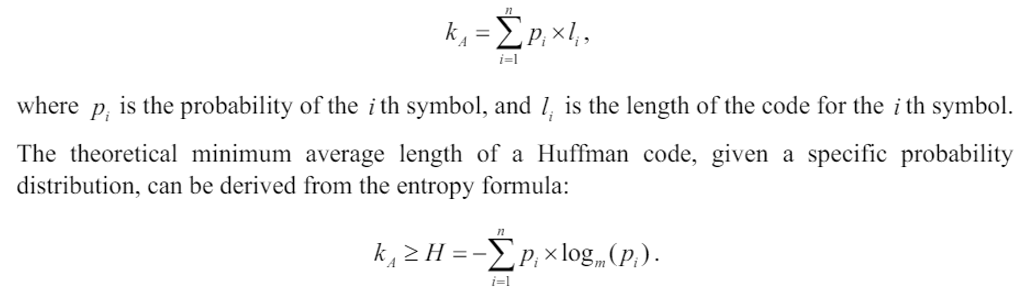
The theoretical minimum average length of a Huffman code, given a specific probability distribution, can be derived from the entropy formula:
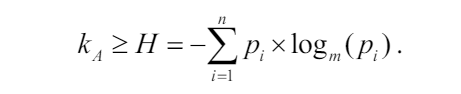
Thus, the efficiency of a Huffman code increases as its average code length approaches the entropy of the distribution.
For the binary tree example ( m = 2 ) discussed, the Huffman code's average length is approximately 3.49 bits per symbol, closely approximating the entropy of the symbol probabilities distribution, which is about 3.46 bits per symbol. These figures suggest that the Huffman code from our example is remarkably close to the theoretical minimum average code length defined by entropy. Ideally, if the code were perfectly optimal, its average length would equal the entropy.
Transforming these assessments into a comparison of the complexity of data integrity verification in both the classical balanced and the proposed adaptive Merkle Tree yields:

The efficiency gain increases with the growing disparity between the probabilities of leaf data. In the extreme case, where one leaf has a 100% probability and all others have 0%, the maximum efficiency gain—up to 100%—can be observed. Although this represents a hypothetical scenario, it is intriguing to model real adaptive Merkle Trees, including non-binary types, and assess the effectiveness of our proposed solution. In Ethereum, Patricia trees are utilized, and our aim is to extend our approach to this case as well. Furthermore, algorithms for the gradual restructuring of balanced trees into an unbalanced form are of particular interest. We propose a protocol for such gradual restructuring, which utilizes newly added nodes to replace high-frequency nodes in the existing tree. These high-frequency nodes are relocated within the tree to positions that correspond to their usage probability, allowing us to incrementally modify the tree's configuration and enhance the efficiency of blockchain integrity checks without a complete overhaul.
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.